Proposed Technical Specification¶
Level 1¶
The specifications for this level are for informational use only and are still under internal development and are not yet finalized. Do not use this version for creating CFDE manifests.
…introduces models for core experimental resources like
- samples and subjects
- search targets in the form of annotations like the anatomical source for a given tissue sample
- host species taxonomy for samples and subjects
- basic support for arranging experimental resources into sub-collections based on a hierarchy of projects or studies
…also introduces two containers for aggregating experimental resources & metadata:
projectdescribes administrative/funding/contract/etc. hierarchy governing ownership/management/purview/responsibility of/for subcollections of experimental resources and metadatacollectionallows any (non-cyclic) groupings to be assigned to subcollections of experimental resources and metadata (independently of contract or funding or ownership or accountability/reporting structures encoded byproject): similar in concept to “dataset” but without implying the existence of a formally-prepared publication-level data package – any coherent and meaningful grouping can be encoded here
|Level 1 model diagram|
|:—:|
|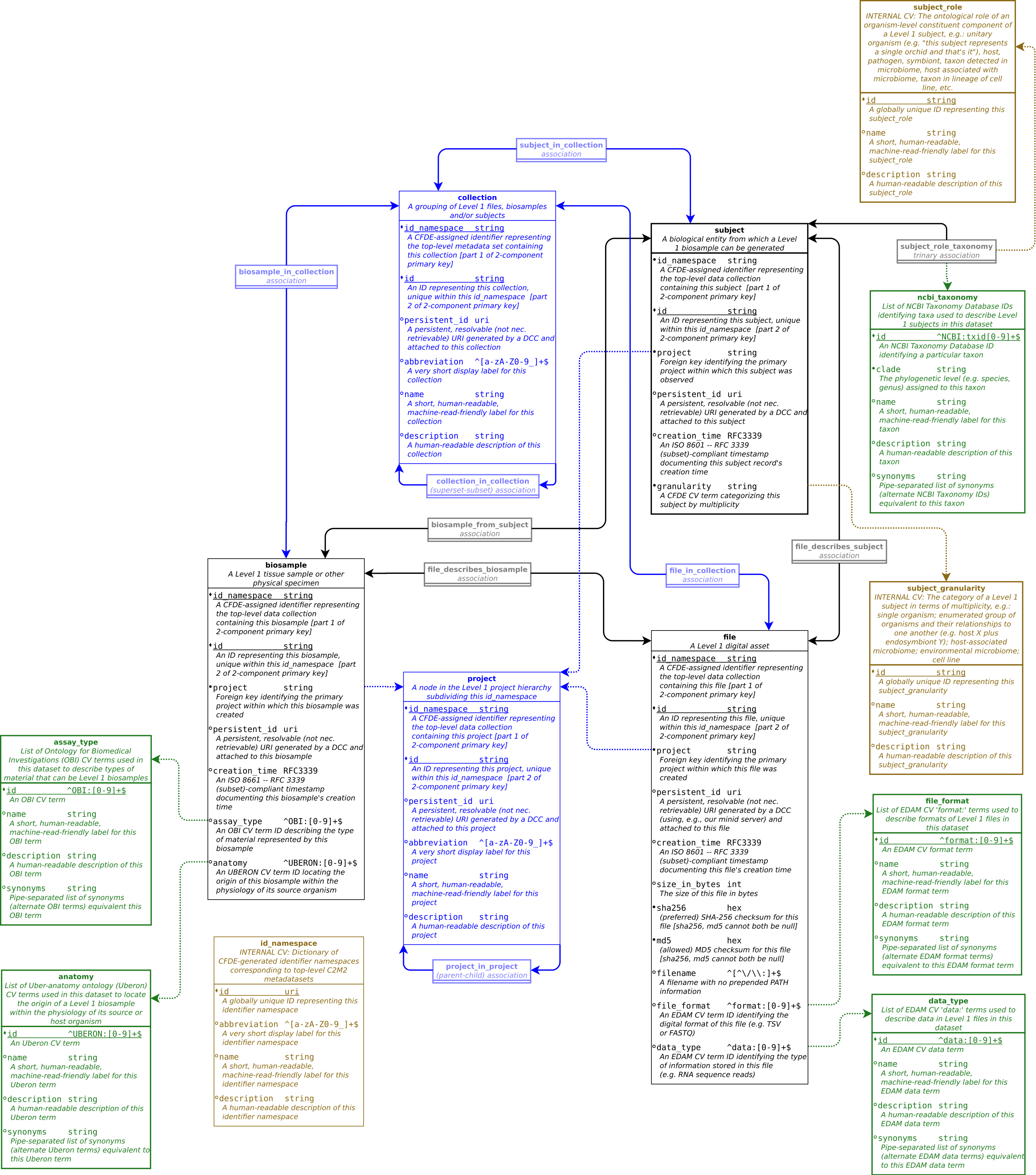 Level 1 model diagram|
Level 1 model diagram|
Level 1 technical specification: the file entity, revisited¶
added properties
Level 1 technical specification: introducing the bio_sample entity¶
added entity: list and define properties
Level 1 technical specification: introducing the subject entity¶
added entity: list and define properties
Level 1 technical specification: using the project table¶
describe the project table
Level 1 technical specification: using the collection table¶
describe the collection table
Level 1 technical specification: using association tables to encode inter-entity relationships¶
describe TSV encoding of bio_sample<->subject<->file<->bio_sample association pairs
Level 1 technical specification: using terms from controlled vocabularies: usage tables¶
enumerate CVs; describe usage tables and outline plan for addressing versioning; discuss parser script, to be executed somewhere in bdbag-preparation stage, which will inflate bare CV terms cited in entity fields into corresponding CV usage tables, loading term-decorator data from relevant CV OBO reference files